
Diese Tabellen werden in SAP verwendet, um IDocs zu speichern:
- Die Tabelle EDIDC – der IDoc-Kontrollsatz
- Die Tabelle EDID4 – die Nutzdaten des IDocs
- Die Tabelle EDIDS – die Statussätze des IDocs
Es lohnt sich, diese Tabellen näher kennen zu lernen, denn sie ermöglichen es Dir, eine Reihe von hilfreichen Auswertungen direkt auf der Datenbank vorzunehmen.
Die Tabelle EDIDC – der IDoc-Kontrollsatz
Die Tabelle EDIDC enthält den sogenannten Kontrollsatz. Dieser enthält grundlegende Verwaltungsdaten des IDocs. Die wichtigsten sind diese:
- STATUS: der aktuelle Status des IDocs. Dies ist gleichzeitig auch der letzte Verarbeitungsstatus aus der Liste der Statussätze (siehe unten)
- DIRECT: die Richtung des IDocs: 1 = Ausgang, 2 = Eingang. Dieses Feld des Kontrollsatzes ermöglicht damit die Filterung nach eingehenden und ausgehenden IDocs
- der Typ des IDocs. Dieser verteilt sich auf zwei Felder:
- MESTYP: der Nachrichtentyp und
- IDOCTP: der Basistyp
- Senderdaten: wo kommt das IDoc her?
- SNDPOR: der Absendeport
- SNDPRT: die Partnerart des Absenders, z.B. LS=logisches System oder KU=Kunde.
- SNDPRN: die Partnernummer des Absenders. Bei Partnerart KU findet sich hier die Kundennummer.
- SNDPFC: („sender partner function“) welche Rolle hat der Sender in diesem Falle? Wenn das Feld gefüllt ist, dann könnte dies z.B. AG für Auftraggeber sein oder WE für Warenempfänger.
- die Empfängerdaten: wo geht das IDoc hin?
- RCVPOR: der Empfängerport
- RCVPRT: Die Partnerart des Empfängers
- RCVPRN: die Partnernummer des Empfängers
- RCVPFC: („receiver partner function“) beantwortet die Frage „welche Funktion hat der Empfänger aus Sicht des Senders?“
- Zeitstempel der Erzeugung und Verbeitung
- CREDAT: Datum der Erzeugung
- CRETIM: Uhrzeit der Erzeugung
- UPDDAT und UPDTIM: dito für das letzte Update der Verarbeitung
Diese Verwaltungsdaten erlauben es Transaktionen wie BD87 oder WE19, nach IDocs eines bestimmten Typs in einem bestimmten Zeitraum zu suchen.
Die Tabelle EDID4 – die Nutzdaten des IDocs
Die Tabelle EDID4 enthält die Nutzdaten des IDocs. Diese Nutzdaten sind in Segmente gegliedert. Jede Zeile der Tabelle enthält ein Segment des IDocs. Die wichtigsten Spalten sind:
- DOCNUM: die Nummer des IDocs. Diese findet sich gleichermaßen auch im Kontrollsatz des IDocs (Tabelle EDIDC).
- SEGNUM: die laufende Nummer des Segments innerhalb des IDocs
- SEGNAM: der Name des IDoc-Segments. Dies ist der Name des Segments aus der IDoc-Definition (Transaktionen WE30 und WE31)
- PSGNUM: die Nummer des hierarchisch übergeordneten IDoc-Segments. Daraus ergibt sich die Hierarchieschachtelung des IDocs in der IDoc-Ansicht, z.B. in den Transaktionen BD87 (IDoc-Übersicht nach Status) oder WE09 (IDoc-Suche nach Inhalt).
- HLEVEL: Hierarchieebene: dies ist das Maß der Einrückung in der hierachischen Ansicht des IDocs in BD87 oder WE09
- SDATA: die Anwendungsdaten. Dieses Feld ist 1000 Zeichen lang. Dieser Characterstring ist in einem ABAP-Programm nicht direkt nutzbar. Man muss diesen Inhalt zunächst direkt auf eine Variable des richtigen Segmenttyps zuweisen, dieser Typ steht in der Spalte SEGNAM. Anschließend kann man dann die einzelnen Felder dieser Struktur ansprechen. Das bedeutet auch: wenn Du eine komplett eigene Verarbeitung für einen komplett neuen IDoc-Typ schreiben willst, dann ist diese Zuweisung ein Stück (Hand-)Arbeit.
Zur Veranschaulichung: die folgende Grafik vergleicht links das IDoc in der Darstellung aus BD87 und rechts die zugehörigen Segmentdaten aus der Tabelle EDID4. Ein Datensatz ist beispielhaft per Pfeil verbunden.
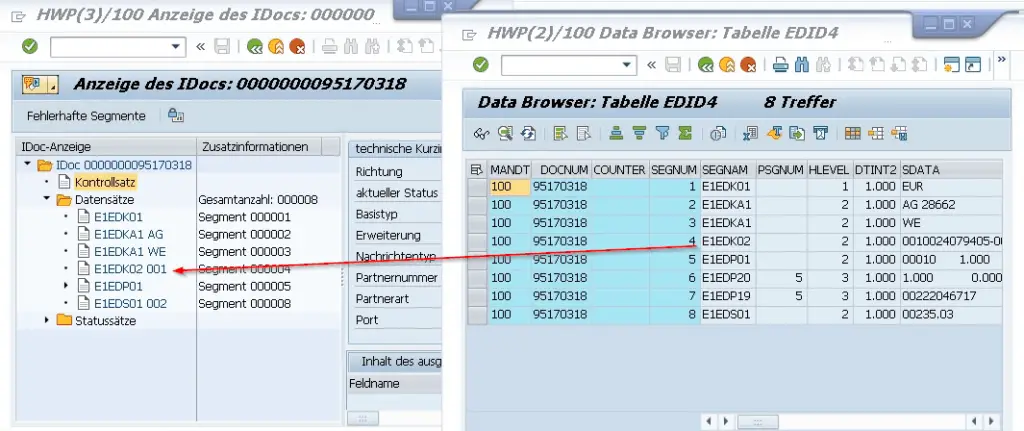
Man sieht im IDoc, dass jedes Segment einen Namen hat, den Zeilentyp. Diese werden in der Transaktion WE30 definiert. Jede Zeile in EDID4 hat ebenfalls den Namen des Segmenttyps. Die Segmente 6 und 7 sind Untersegmente von Segment 5. Links in der Grafik könnte man den Knoten 5 aufklicken, um diese Segmente anzuzeigen. Dort wo Untersegmente auftauchen, steigt in EDID4 der Hierarchielevel.
Die Länge von SDATA ist für die IDoc-Definition zentral. Diese Tabellendefinition beschränkt die Länge jedes Segments auf 1000 Zeichen. Das hat eine wichtige Konsequenz:
Mal angenommen, Du erweiterst über mehrere Jahre hinweg einen IDoc-Typ, um neue Anforderungen zu erfüllen, dann kann der Zeitpunkt kommen, an dem das Segment nicht mehr vergrößert werden kann. In diesem Fall müsstest Du dann ein weiteres Segment definieren, das die neuen Felder aufnimmt. Das ist dann möglicherweise aufwändig.
Es lohnt sich daher, bei Segmenterweiterungen rechtzeitig sparsam zu sein. 4 Felder mit char255 machen das Segment nämlich schon voll.
Die Tabelle EDIDS – die Statussätze des IDocs
Die Tabelle EDIDS enthält die Statussätze des IDocs und damit das Verarbeitungsprotokoll. Jeder Verarbeitungsschritt des IDocs erzeugt hier eine oder sogar mehrere Zeilen.
Die wichtigsten Spalten lauten:
- DOCNUM: die Nummer des IDocs. Diese steht auch gleichermaßen im zugehörigen Kontrollsatz in der Tabelle EDIDC.
- Der Zeitstempel des Logeintrags. Er besteht aus LOGDAT, dem Datum und LOGTIM der Uhrzeit.
- COUNTR: die laufende Nummer des Logeintrags. Dieses Feld dient dazu, verschiedene Zeilen bei gleicher Uhrzeit erzeugen zu können.
- STATUS: der Statuswert, der mit dieser Zeile erreicht wurde. Der Statuswert der letzten Verarbeitung findet sich zumeist auch im Kontrollsatz. Es ist natürlich auch möglich, den Statussatz des gesamten IDocs zu ändern, ohne einen Logeintrag dazu zu schreiben. Üblicherweise sollte das aber korrespondieren.
- STATTTEXT: die Meldung im Volltext. Diese speist sich aus dem SAP-Messagesystem:
- STAMID und STAMNO nennen, wo die Vorlage für STATTEXT herkommt. Dies sind die Nachrichtenklasse und die Nachrichtennummer aus der Transaktion SE91. Hier können bis zu vier Parameter mitgegeben werden. Diese finden sich dann in den Feldern STAPA1 bis STAPA4.
Auch hier zur Veranschaulichung der direkte Vergleich: oben ist dasselbe IDoc in BD87, unten ist die Liste der Statussätze aus EDIDs:
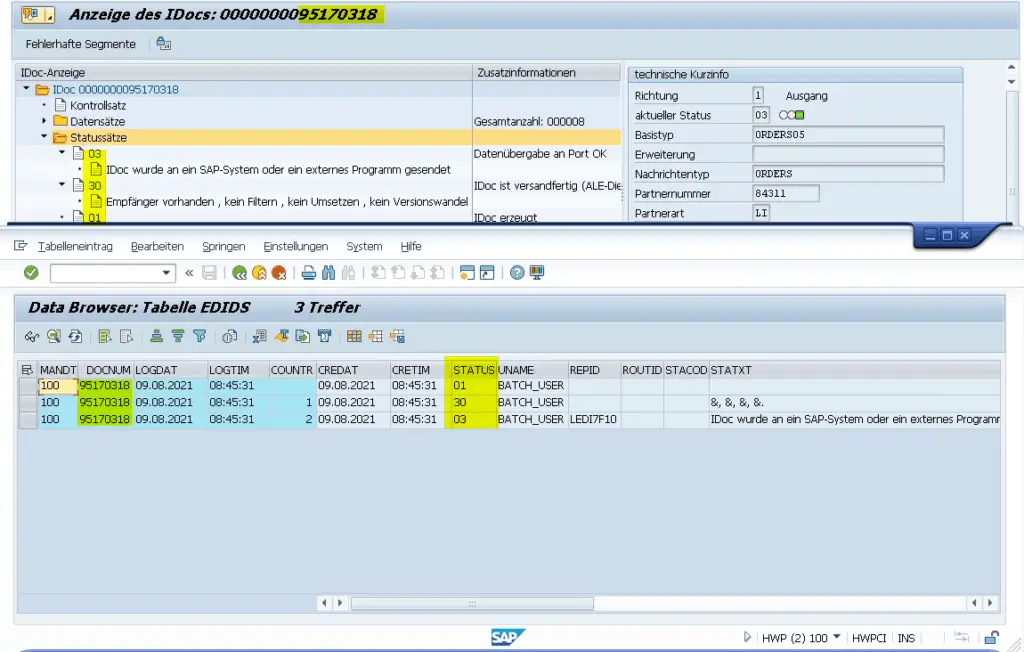
Für jeden Statussatz aus der IDoc-Anzeige findet sich eine eigene Zeile in der Tabelle EDIDs.
Direkte Auswertungen von IDocs auf den Tabellen
Wie oben erwähnt, lassen sich manche Auswertungen von IDocs auch direkt auf den Tabellen machen. Hier einige Beispiele:
Du stellst fest, dass ein IDoc auf einen seltenen Fehler gelaufen ist und Du fragst Dich, ob dieser Fehler öfter aufgetreten ist. Zu dem Fehler wurde auch eine Zeile im Verarbeitungsprotokoll EDIDS geschrieben. Du holst Dir die Nachrichtenklasse und die Nachrichtennummer und selektierst dann auf EDIDS, wann dieser Fehler noch aufgetreten ist.
Aber auch statistische Auswertungen sind möglich. Ein Kunde, für den ich arbeite, hat z.B. einen Import von Aufträgen aus dem Webshop gebaut. Ziel ist es, diese Aufträge möglichst automatisch zu verbuchen. Es kann aber aus einer ganzen Reihe von Gründen vorkommen, dass Aufträge zur manuellen Nachbearbeitung ausgesteuert werden. Vielleicht ist die Adresse unbekannt. Vielleicht ist ein Artikel nicht verfügbar, etc. Hierüber wird regelmäßig eine Statistik errechnet, um einen beständig hohen Automatisierungsgrad zu erreichen. Auch hier wird EDIDS ausgewertet.
Datenselektionen sind ein weiterer interessanter Bereich. Die Möglichkeiten sind hier aber eingeschränkt. Die Datentabelle EDID4 ist eine sogenannte Clustertabelle. Diese ermöglicht es SAP, die Daten platzsparender abzulegen. Allerdings bedeutet dies, dass in der Datenselektion in SE16 auf diese Spalte nicht selektiert werden kann. Ein *123456789* für die Suche nach dieser Rechnungsnummer funktioniert damit leider nicht. Allerdings kannst du Zeilen aus EDID4 mit SE16 selektieren und danach in der Anzeige nachträglich filtern. Hier stehen die normalen Filtermöglichkeiten aus ALV-Grids zur Verfügung. Dies funktioniert zumindest auf demjenigen Teil von der Spalte SDATA, der in SE16 zu sehen ist. Die Spalten der Nutzdaten aus der Segmentdefinition liegen ohne Punkt und Komma hintereinander weg in einem einzelnen Textstring. Im Vergleich mit der tatsächlichen Struktur der Daten sind diese zumindest einigermaßen lesbar.
Mehr SAP-Tipps findest du hier.